鉴定AlexNet、ZFNet、VGG、GoogLeNet等热门卷积神经网络
本文最后更新于:4 天前
打卡计算机视觉–纹理表示和卷积神经网络, 帮助快速简单的理解,适合有一定基础的计算机视觉选手。
经典网络解析
本文旨在解析前几年部分经典神经网络的实现结构,需要一些优化算法、全神经网络等储备知识,有不明白的可以向我提问。
以下介绍的神经网络大体相似,区别只在神经网络的步步优化方面,比如从大卷积核到多次小卷积核卷积、复杂特征卷积核提取增多等等。
AlexNet神经网络
AlexNet神经网络是神经网络逐渐从人们视野中淡化再到复出的一个转折点,它是2012年ImageNet视觉识别挑战赛的冠军模型
主体贡献
- 提出了一种卷积层加全连接层的卷积神经网络结构(让神经网络从人们视野中复出)
- 首次使用ReLU函数做为神经网络的激活函数(不会因为输入值的大小而输出接近0或1而断掉特征数值的传递)
- 首次提出Dropout正则化来控制过拟合(解决了神经网络参数多而容易过拟合的缺点)
- 使用加入动量的小批量梯度下降算法加速了训练过程的收敛(降低计算量,在优化参数上更快找到最低点)
- 使用数据增强策略极大地抑制了训练过程的过拟合(数据增强比如说图像反转、放大缩小等,增加样本量)
- 利用了GPU的并行计算能力,加速了网络的训练与推断(利用显卡优秀的矩阵计算能力进行实现模型)
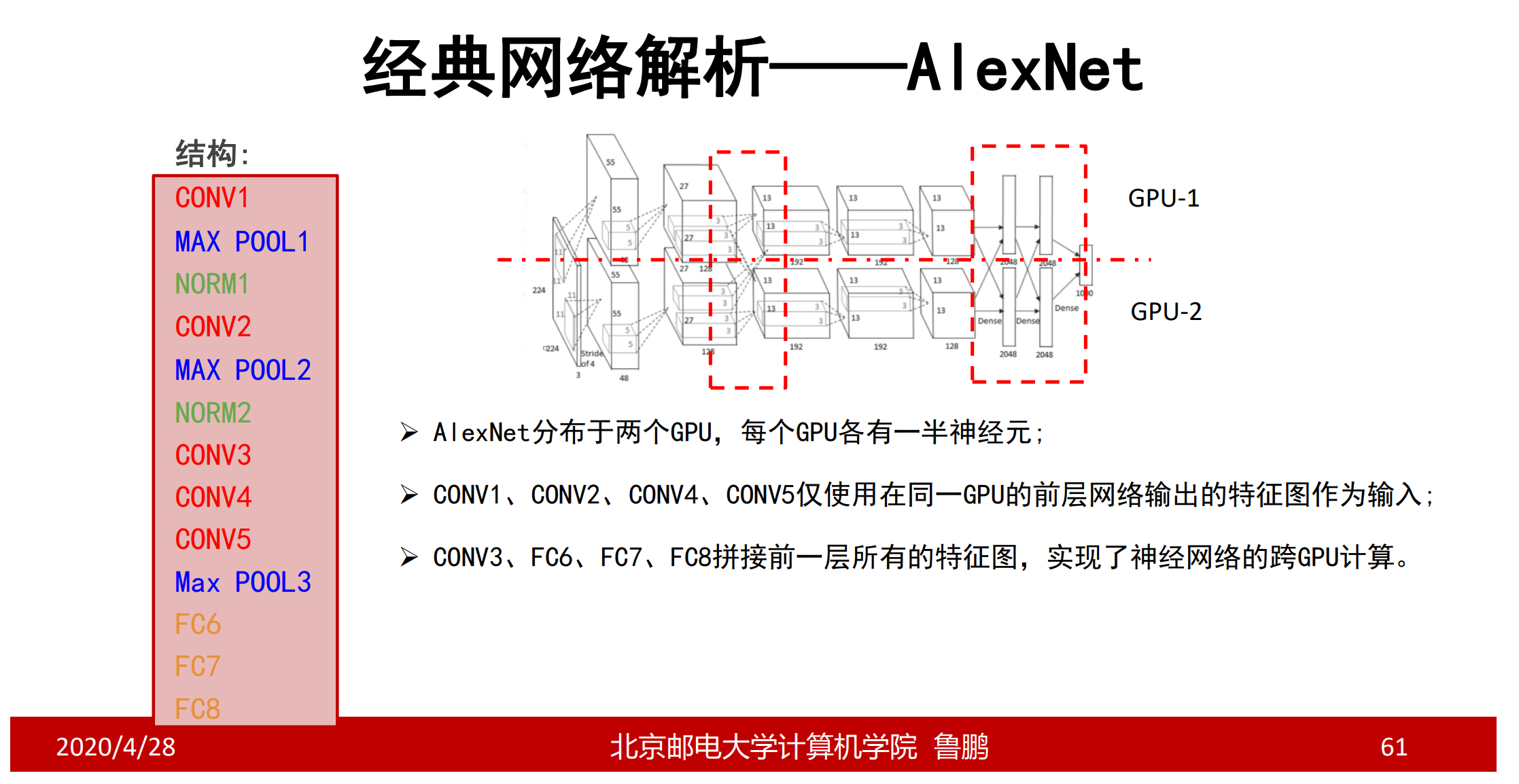
神经网络模型

CONV1:96个11 * 11卷积核,步长为4,无零填充
MAX POOL1:窗口大小3 * 3,步长为2 降低图像尺寸,重叠有助于对抗过拟合
NORM1:现在不怎么用了,不做解释
CONV2:256个5 * 5卷积核,步长为1,使用零填充p=2
CONV3、CONV4:384个卷积核,步长为1,使用零填充p=1
CONV5:256个3 * 3卷积核,步长为1,使用零填充
卷积神经网络输出为6 * 6 * 256,以此输入到全连接神经网络中
- 用于提取图像特征的卷积层以及用于分类的全连接层是同时学习的
重要技巧:
- Dropout策略防止过拟合
- 使用加入动量的随机梯度下降算法,加速收敛
- 验证集损失不下降时,手动降低10倍的学习率
- 采用样本增强策略增加训练样本的数量,防止过拟合
- 集成多个模型,进一步提高精度
理解卷积层
卷积层就像各种偏导核一样,从多种偏导核中提取偏导核对应的特征,不同的是卷积层对应的是高级复杂的特征,甚至不能称之为特征而是结构。

ZFNet神经网络
ZFNet神经网络与AlexNet神经网络结构基本一致
主要改进:
- 将第一个卷积层的卷积核大小改为了7 * 7
- 将第二、第三个卷积层的卷积步长都设置为2
- 增加了第三、第四个卷积层的卷积核个数

改进理解:
- 减少第一层的卷积核大小,可以提取到更加细致的特征
- 步长设置为2,多次分批缓慢降低图像大小,不会损失过多信息
- 增加第三层第四层卷积核,后层的卷积核以及存在语义信息,个数增多能够学习更多复杂语义特征
VGG神经网络
主要以VGG16为例讲解
模型特征:

主要改进:
- 使用尺度更小的3 * 3卷积核串联来获取更大的感受野
- 放弃使用11 * 11和5 * 5这样的大尺寸卷积核
- 深度更深、非线性更强,网络参数也越少
- 去掉了AlexNet中的局部响应归一化层
改进优势:
- 以多个小卷积核多次卷积代替大卷积核一次卷积,二者的感受野相同但是非线性更强、深度更深且计算量少
- 池化操作后增加卷积核一倍,池化降低图像大小而卷积核个数有助于学习到更多特征,一增一减平衡识别精度、计算开销提升网络性能
GoogLeNet神经网络

创新改进:
- 提出了一种Inception结构,它能保留输入信号中的更多特征信息
- 去掉了AlexNet的前两个全连接层,并采用了平均池化,这一设计使得 GoogLeNet只有500万参数,比AlexNet少了12倍
- 在网络的中部引入了辅助分类器,克服了训练过程中的梯度消失问题
改进优势:
改变串行结构,串行因为结构后一卷积层只能接受前一卷积层的输出,无可避免会丢失信息,而并行结构分别以1 * 1卷积核、3 * 3卷积核、5 * 5卷积核和增强池化层为输入,同时兼顾各式卷积的特征结果提取特征。
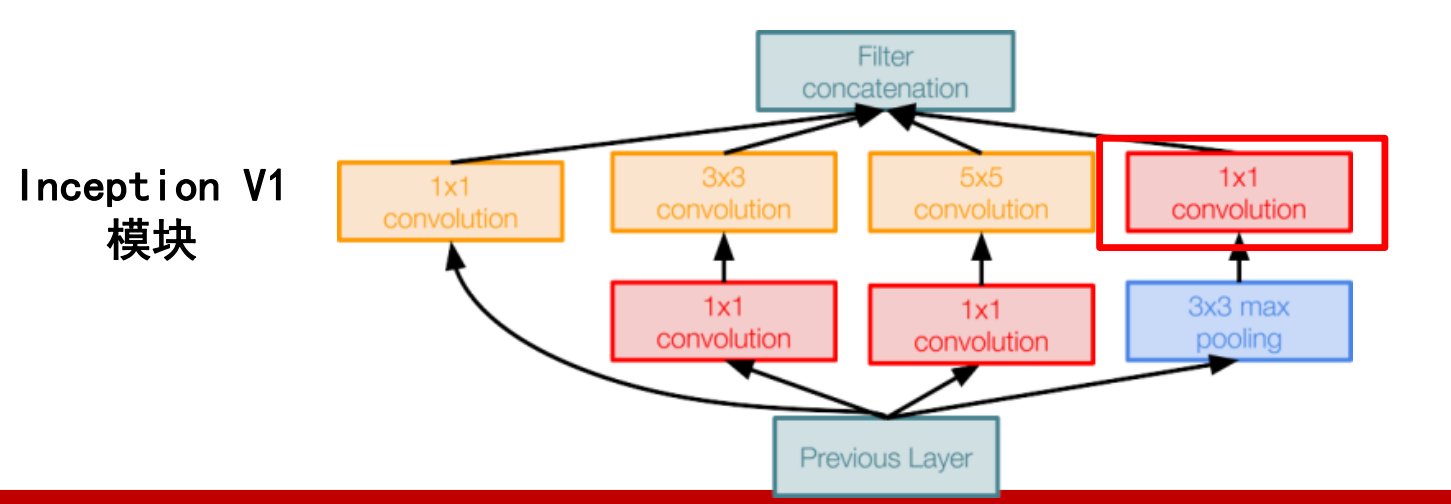
标记的红框1 * 1卷积核作用只为减少运算量,以多个1 * 1卷积核代替直接使用图像,以卷积核个数维度代替图像大小值,可大量减少计算量,层数更深、 参数更少、 计算效率更高、非线性表达能力也更强
辅助分类器作用:避免激活函数梯度消失问题,使得梯度回传更好训练模型
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载先请联系作者且注明出处!